
小売の現場でさ、朝イチに「今日の売上どう?」って聞かれて、昼に「在庫足りてる?」って詰められて、夕方に「返品ポリシー的にそれOK?」って来て。
ダッシュボードは3つ開いて、SQLは誰かが書いた謎のやつで、ポリシーPDFはSharePointの奥底。
で、結局ぜんぶ人間が右往左往して答えるやつ。あるある。😮💨
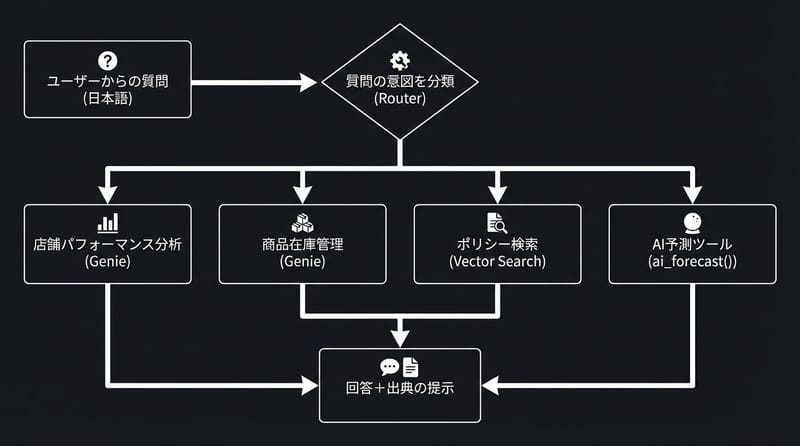
結論:Databricks Apps上でStreamlit+OpenAI Agents SDKを組むと、Genie rooms・Vector Search・ai_forecast()を1つの会話UIに束ねて、権限付きで店のKPI・在庫・規程・予測まで同じ窓から引ける。
- 道具の分離:Genie roomsを「部門ツール」として切る(売上系/在庫系)
- 規程はRAG:Databricks Vector Searchでポリシー文書を検索して文脈注入
- 予測はML:ai_forecast()を会話から呼んで“数字”を返す
- 配布はApps:Databricks Appsでデプロイ、Secretsとアクセス制御も一緒
- 監視は痕跡:Databricks Agent Monitoringでトレースとレイテンシ見える化
- これ、ちゃんと「企業内で運用できる会話アプリ」の型なんだよね
まずこれ何を作ってるのかって話
Store Intelligence Assistantは、Streamlitの対話UIから自然文で質問すると、Databricks Genie rooms・Vector Search・ai_forecast()をOpenAI Agents SDKが編成して答えを返すエンタープライズ向け分析アプリだ。
いわゆる「チャットボット」って言うと軽いけど、実態は“ツールの束ね役”だよね。
会話は入口。
中でやってるのは、KPIはSQL/メトリクス、規程はベクトル検索、予測はモデル呼び出し。ぜんぶ別々の筋肉。
地味に効くポイント:LLMはDatabricksのMosaic AI Gateway上のエンドポイントとして用意して、アプリ側はそれを叩く。企業のネットワークとガバナンスの文脈で「そこ置くのが現実」ってやつ。
うっかり外のAPI直で…みたいな構成だと、あとから監査で死ぬ。ほんとに。
Genie roomsをツール扱いにするのがうまい
Databricks Genie roomsを専門ツールとして分けると、ドメイン別の質問をそれぞれの部屋に投げられて、権限も最小化できる。
これ、妙に刺さる。だって部門って、混ぜると燃えるから。
原文の構成だと部屋は2つ。
- Store Performance Genie room:売上、トレンド、来店(foot traffic)、BOPIS、会員更新、粗利、あとai_forecast()で売上予測
- Product Inventory Genie room:店頭在庫(on-hand)、安全在庫(safety stock)、発注点(reorder point)、発注残(on-order)
で、ここが気持ちいいのが、各部屋が独立して育つところ。
売上側だけ「月次予測をその場で出す関数」を仕込む、とかね。
在庫側は在庫側で、閾値や発注ロジックのクセがある。
混ぜない。分ける。
「エージェントをツールとして扱う」って発想が、OpenAI Agents SDKの推奨パターンに沿う、ってのがまた現実的でイヤに強い。
権限の話:部屋ごとにアクセス制御を切れるし、マスキングルールも噛ませやすい。つまり、経理の数字を在庫チームに“うっかり見せない”がやりやすい。
ここで事故ると、Slackが凍る。😇

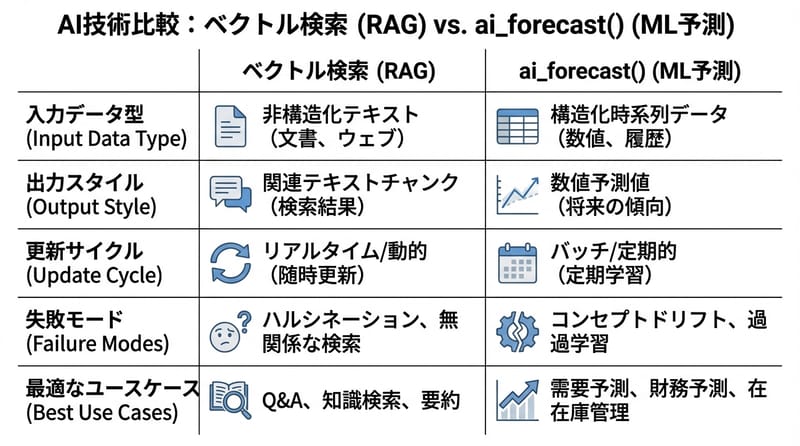
ポリシーとか規程はVector Searchが一番早い
返品手続きや行動規範などの非構造ドキュメントは、Databricks Vector Searchでチャンク化・埋め込み・索引化して、質問時に近い断片を取り出すのが定番になる。
表に入らない文章、表に入れようとするとだいたい泣く。
やり方はわりと素直で、原文もこの流れ。
- ドキュメントを意味のある塊に分割(chunk)
- 各chunkを埋め込みモデルでembedding化
- embeddingをDatabricks Vector Search indexに保存
- 問い合わせ時にindex検索→関連chunkをコンテキストに注入→回答
で、サーバレスエンドポイントとして露出できるから、エージェント側からは「必要なら呼ぶ道具」になる。
レイテンシも抑えやすい。ここは運用で効いてくる。
ありがちな事故:ポリシー文書が更新されてるのに、ボットが古いルールを言う。
だから“同期してインデックス更新できる設計”が前提になる。更新頻度が高い業務、ここで詰む。
ai_forecastでクラシックMLを会話に混ぜる
Store Performance Genie roomからDatabricksのai_forecast()を呼ぶと、会話の中で売上予測などの時系列予測を返せる。
GenAIだけだと、予測が“雰囲気”になりがちだからね。
この混ぜ方、好きなんだよな。
予測は予測で、ちゃんとモデルが数字を出す。
会話はそれを解釈して、言葉にする。
さらに:原文がさらっと言ってるけど、同じパターンでModel Servingのエンドポイントも叩ける。つまり、既に動いてる従来ML(需要予測、離反、異常検知…)を、会話の“増強パーツ”として再利用できる。
捨てない。載せる。
これが現場の勝ち筋。たぶん。
Databricks Appsで配布まで一気にやる
Databricks Appsを使うと、Streamlitアプリをワークスペース内でデプロイして、Secrets管理やアクセス制御と一緒に運用に乗せられる。
“動いた”と“使える”の間の谷、ここで埋める感じ。
デプロイ手順は原文の通りで、割と型が決まってる。
1) Databricks workspaceにsecretsを作る
2) databricks apps create <app-name>
3) databricks sync --watch でローカルと同期
4) databricks apps deploy <app-name>この「sync --watch」って、地味に精神衛生に効く。
デプロイの往復が速いと、設計が雑でも立て直せる。いや、雑はダメなんだけど。😅
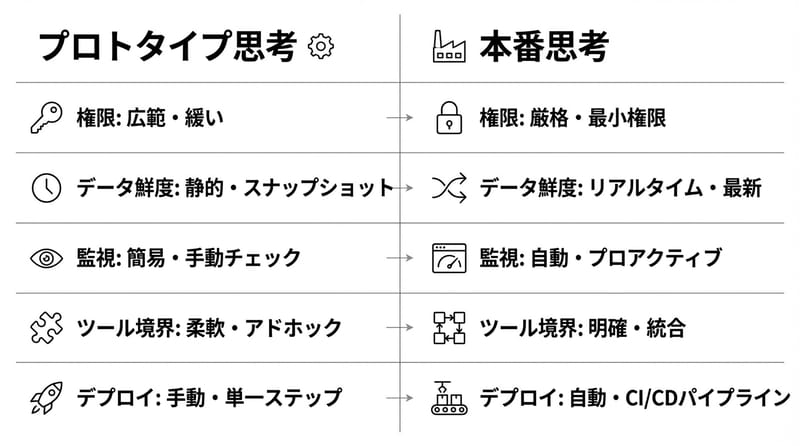
監視しない会話アプリはだいたい闇落ちする
Databricks Agent Monitoringを入れると、エージェントのトレースがDatabricksに戻って、リクエスト数・レイテンシ・トークンなどの運用メトリクスが見える。
可観測性があると、改善が“気合”じゃなくなる。
ここ、ほんと現場っぽい話で。
最初は動くんだよ。
でも、ある日突然「今日は遅い」って言われる。
その時に、どのツール呼び出しが詰まってるか、プロンプトが肥大化してないか、Vector Searchのヒットがズレてないか。
見えないと、全部“体感”になる。
体感運用、しんどい。ほんとに。😵💫
スクショ用の自分チェックリスト置いとく
規則:これは「作る前に詰むポイント」を潰す用。スクショしてチームのチャットに投げるやつ。
- 質問の種類が3つに分かれてる? KPI/在庫/規程(+予測)を混ぜてない?
- Genie roomsの境界が言語化できる? どの質問がどの部屋に落ちるか、説明できないと運用で揉める
- 権限設計が先? 部屋ごとにアクセス制御、マスキングの前提がある?
- 非構造データはVector Searchに寄せた? PDFをテーブルに入れようとしてない?(やめとけ)
- チャンク戦略ある? 規程文書、1チャンクが長すぎると当たり前に外す
- 更新頻度の想定ある? ポリシー更新→index更新が遅れると事故る
- 予測は“雰囲気”じゃない? ai_forecast()やModel Servingで数字を出す導線がある?
- エンドポイントの置き場は決めた? Mosaic AI Gatewayで管理する前提になってる?
- デプロイ手順が再現できる? secrets→create→sync→deploy、誰がやっても同じ?
- 監視が最初から入ってる? Agent Monitoringでトレースが取れる?
- 失敗パターンを書いた? 「Vector Searchが外す」「権限で弾く」「予測が欠損」時の挙動
これ埋まってないまま進むと、あとで泣くのはだいたい運用担当。
未来の自分が怒ってくる。笑
結局この構成の強さって何なの
このアーキテクチャの強みは、Vector SearchのRAG、Text-to-SQLの分析、ai_forecast()の予測、Genie roomsの専門性、Databricks Appsのデプロイと統制を、OpenAI Agents SDKで一つの会話フローに束ねた点にある。
単機能のボットじゃなくて、「企業内の道具箱を会話で引き出す」って形になる。
でさ、ここからが個人的に熱いところ。
会話UIって、KPIを見に行く人だけじゃなくて、見に行かない人も巻き込むじゃん。
現場の人が“言葉”で聞けるのは強い。
ただ、言葉で聞けるようにした瞬間、ガバナンスと観測が必須になる。
楽になった分、責任も増える。うん。
最後に一個だけ:この手の話、みんなの「一番しんどかった事故」どれ?
権限で燃えたやつ?ポリシーの古い版を答えて炎上したやつ?それとも、レイテンシ地獄で“使われなくなった”やつ?
比惨大会しよ。こっちもネタある。😑


