
最近、PostgreSQLのコストについてよく考える。特にクラウド。便利だけど、請求書見てびっくり、みたいな話が多すぎる。
「先月まで5万円だったDBが、今月500万円に…」なんて冗談みたいな話が、マジであるから怖い。トラフィックが急増したわけでもないのに。クラウドのマネージドDBって、静かにリソースを食い尽くす時限爆弾みたいだなって思う。
で、結論から言うと
クラウドのマネージドPostgreSQL、例えばAWSのRDSとかね。あれ、実はハードウェアスペックが同じEC2インスタンスで自前構築するより、平気で4倍とか高い。400%。これ、ほとんどの人が気づいてないか、見て見ぬふりをしてる「公然の秘密」みたいなもの。
便利さとか、自動化とか、そういう言葉の裏に隠された、とんでもないマークアップ。正直、スタートアップの予算なら一撃で吹き飛ぶレベル。

どこでコストが爆発してるのか?
じゃあ、具体的に何がそんなにお金を食ってるのか。だいたい犯人はこの3つ。
1. ストレージの罠
まず、ストレージ。クラウドベンダーはコンピューティング(CPU/メモリ)とストレージを別々に請求してくる。で、両方にプレミアム料金を乗せてくるわけ。
例えば、データが500GB、インデックスが200GB、ログが100GB。合計800GB。RDSだと、月々1GBあたり$0.115とかで、これだけで$92。さらに自動バックアップでも料金がかかるから、合計で月$168とかになる。これをEC2上のSSD(EBS)でやれば、月$64くらい。ストレージだけで毎月1万円以上損してる計算。
知らないうちにどんどん膨らむ。これが一つ目の罠。
2. コネクションの無駄遣い
これが一番よく見るパターンかも。アプリケーションがDBコネクションを最適化してないせいで、無駄にハイスペックなインスタンスを使わされる羽目になる。
よくあるのが、アプリのサーバーインスタンスがそれぞれ20個とかコネクションを張るコード。サーバーが10台になったら、それだけで200コネクション。こうなると、もう月$70の安いインスタンスじゃ捌けなくて、「もっとメモリが多いやつにしろ」って言われて、月$180のインスタンスにアップグレードさせられる。マジでよくある。
解決策は単純で、コネクションプーラーを挟むだけ。PgBouncerとか。アプリの各インスタンスからのコネクションを5個とかに絞って、PgBouncerがうまいこと使い回してくれる。そうすれば、DB側はせいぜい50コネクションで済むから、安いインスタンスのままでいける。これだけで月1万円以上の節約。
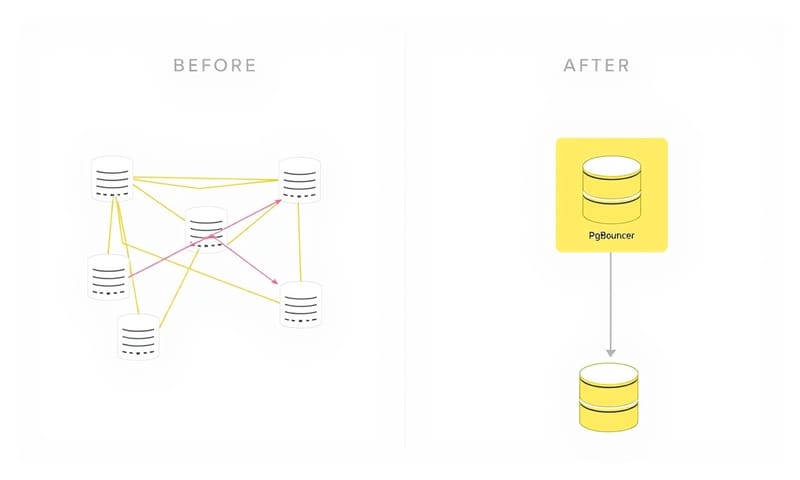
3. リードレプリカの増殖
読み込みが遅い?「じゃあリードレプリカを増やしましょう!」って、クラウドベンダーの営業やコンソールはすぐ言ってくる。でも、これってコストが単純に倍々ゲームになるだけ。
プライマリDBが月$350だとして、リードレプリカを3台追加したら、それだけで$1,050。合計$1,400。バカらしいでしょ。
でもね、これもさっきのコネクションプーリングで解決したり、もっと言えば、そもそもそんなにリアルタイム性が必要ないクエリなら、マテリアライズドビュー(集計結果を予めテーブルとして持っておく機能)を使えばいい。1時間に1回更新、とかで十分なケースは山ほどある。そうすれば、リードレプリカなんていらなくて、プライマリDB1台(月$350)で済む。95%のコスト削減、とかも全然夢じゃない。
-- マテリアライズドビューの例。ダッシュボードの裏側とかで使う
CREATE MATERIALIZED VIEW daily_user_metrics AS
SELECT
date_trunc('day', created_at) as day,
count(*) as new_users,
sum(revenue) as daily_revenue
FROM users
GROUP BY date_trunc('day', created_at);
-- これをpg_cronとかで定期的にリフレッシュするだけ
SELECT cron.schedule('refresh-metrics', '0 * * * *', 'SELECT REFRESH MATERIALIZED VIEW CONCURRENTLY daily_user_metrics;');
ほら、これでリードレプリカ5台分の仕事が、ほぼタダでできる。
じゃあ、どうすりゃいいの?
選択肢は「自前でやる(セルフマネージド)」か「賢く使う(ハイブリッド)」か。
全部をRDSからEC2に載せ替えるのは大変…って思うかもしれない。わかる。でも、全部やる必要はない。ハイブリッドがいい落とし所だったりする。
- 開発/ステージング環境:ここはRDSでいい。すぐ作ってすぐ壊せるし、メンテの手間をかけたくない。
- 本番環境:ここだけEC2とかコンテナで自前運用する。コストとパフォーマンスを完全にコントロールできる。バックアップもS3 Glacierみたいな安いストレージに自分で送れば、劇的に安くなる。
これはAWSだけの話じゃなくて、GCPのCloud SQLとかAzure Database for PostgreSQLでも構造は同じ。ベンダーにロックインされると、こういう高い料金を払い続けることになる。
マネージド vs 自前運用、どっちがいいの?
結局、どっちがいいかはチームの状況次第。整理してみると、こんな感じ。
| 比較ポイント | クラウドマネージド (RDSとか) | 自前運用 (EC2+Dockerとか) |
|---|---|---|
| コスト | 高い。ハードウェア代の3〜5倍は見ておいた方がいい。 | 安い。インフラの実費だけ。でも人の時間はかかる。 |
| コントロール | ほぼない。パラメータもいじれる範囲が限られてる。 | 全部できる。OSレベルからPostgreSQLのconfまで。最高。 |
| 必要な専門知識 | 最低限でOK。ポチポチすれば動くからね。でもトラブル時は沼。 | DBとインフラの知識が必須。ないと逆に高くつく可能性も。 |
| スピード感 | 初期セットアップは爆速。レプリカ追加も数クリック。 | 初期構築は時間がかかる。Terraformとかで自動化しとかないと辛い。 |
| 向いてるケース | DBコストが月20万以下。プロトタイプ。DBの専門家がいないチーム。 | コストが無視できなくなってきた。パフォーマンスを突き詰めたい。 |
逃げ出すための具体的なステップ
もし「もう無理、高すぎる」ってなったら、移行は不可能じゃない。ちゃんと計画すればできる。
- 評価と計画:まず、今のRDSのコストと性能をちゃんと把握する。CloudWatchのメトリクスとか見て、本当にそのインスタンスサイズが必要か?とか。
- インフラ構築:Terraformとかで新しいEC2インスタンスとかVPCをコード化して作る。後で再現できるように。
- データ移行: `pg_dump` と `pg_restore` でデータを移すのが基本だけど、ダウンタイムを許容できないなら、ストリーミングレプリケーションを設定して、最後に切り替える、とか。
正直、この辺は専門知識がいる。でも、一度このスキルを社内に貯めれば、それはもうすごい競争力になる。日本の企業だと、この辺のインフラ専門家を正社員で雇うと年収1000万円超えたりするけど、外注したり業務委託で頼む手もある。長期的に見れば、毎月クラウドベンダーに何百万円も払い続けるより絶対安い。
アメリカの বড়テック企業、例えば Netflix のような会社は、こういうインフラの最適化を自社で徹底的にやってるから、あの規模のサービスを回せている。彼らのブログとか見ると、かなり参考になることが多い。
まとめ:そろそろ目を覚ます時間
クラウドのデータベースコストが爆発するのは、事故じゃなくて、ビジネスモデル。ベンダーは「DB管理は複雑で危険だから、我々に任せなさい」って言って、その安心料として莫大な利益を得てる。
でも、DockerとかAnsible、Terraformみたいなモダンなツールのおかげで、DB管理のハードルは昔よりずっと下がってる。この事実に気づいて、自社でノウハウを蓄積する会社が、結局は生き残るんだと思う。便利さに思考停止して、お金を垂れ流し続けるか。それとも、ちゃんと技術に投資して、持続可能な成長を手に入れるか。
個人的には、DBの専門知識は「負債」じゃなくて「競争優位」だと思う。さて、あなたのチームはどうする?
あなたのチームでは、データベースのコストが月いくらを超えたら「自前運用」を検討し始めますか? よかったらコメントで教えてください。
- A) 20万円超えたら
- B) 100万円超えたら
- C) 金額じゃなく、パフォーマンスが問題になったら
- D) 絶対に自前運用はしない


