
Kubernetes運用の隠れた落とし穴を事前に防ぐ実践ポイント
- 毎週リソース使用率をメトリクスで可視化・確認する
過剰消費や不足の傾向がすぐ見え、突然のクラッシュや性能低下を予防できる
- 全Podに対しCPU・メモリのrequests/limitsを必ず設定(未設定ゼロ件へ)
急な負荷時にも他サービスへの影響やノード障害が減る
- 死活監視プローブ(liveness/readiness)失敗数10件未満か毎月チェック
異常検知まで遅延せず、サービス停止時間が短縮される
- (状態保存アプリは) StatefulSet+永続ストレージ利用率80%以下キープ
データ消失リスクとストレージ枯渇による再起動連鎖を回避できる
深夜のKubernetesクラスタが資源を貪り食う謎に直面した話
3年前、真夜中の1時。アパートで画面を見つめながら、なぜ自分のKubernetesクラスターが貪欲なモンスターのようにリソースを食い尽くすのか、頭を抱えていました。公式ドキュメントはあたかも簡単そうに見せ、YouTubeのチュートリアルは「誰にでもできる」と謳っていました。それなのに現実は——この惨状です。「この苦労って自分だけ?」と何度も自問しましたが、答えはNOでした。
今では数千人規模の本番環境Kubernetesクラスターを複数管理していますが、ここに至る道のりは決して平坦ではありませんでした。当時誰も教えてくれなかった「日常的に襲いかかるKubernetesの地雷」と、私なりの解決策を赤裸々にお伝えしましょう。
最初に直面したのは「リソース設定の落とし穴」です。クラスター構築そのものより、効率的な運用こそが本当の難関でした。深夜帯に突如発生するメモリリークや、開発者が気付かぬ間に蓄積するゴミPod——PrometheusとGrafanaで可視化してみると、まるで心電図のように乱高下するメトリクスグラフに慄然としたものです。特に厄介だったのがCronJobの暴走で、うっかりCPUリクエストを設定忘れたバッチ処理がノード全体を麻痺させた夜は、冷や汗ものでした。
Horizontal Pod Autoscaler(HPA)の閾値調整にも随分苦労しましたね。「80%利用率でスケールアウト」といった単純な設定では、急激なトラフィック増加に対応できず、結局手動介入が必要になることもしばしば。最終的には時間帯別ポリシー(深夜帯は控えめにスケールインなど)を導入し、kubecostでコスト分析しながら最適化していきました。
リソース制限の設定がジェリービーンの数を当てるような苦労だった日々
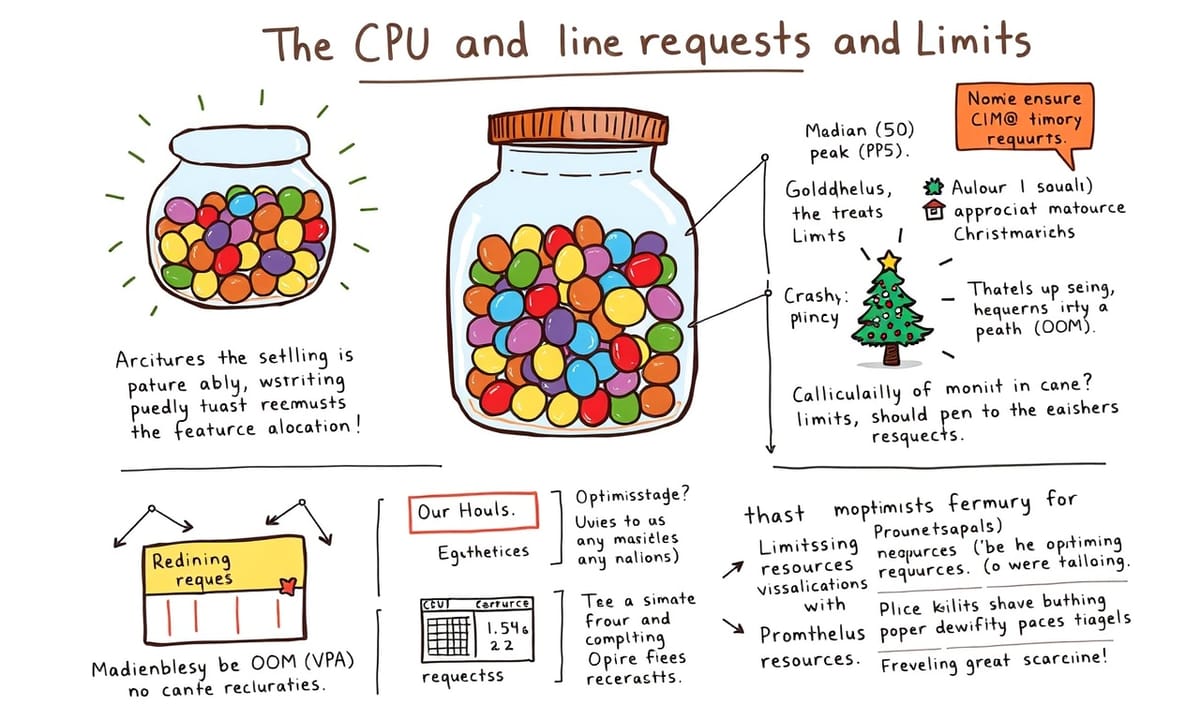
「適切なCPUとメモリのrequestsとlimitsを設定すれば大丈夫」ってみんな言うんですよね。でも実際にやってみると、巨大な瓶に入ったジェリービーンの数を当てるようなものだってこと、誰も教えてくれなかったんです。値を低く設定しすぎると負荷時にアプリがクラッシュするし、高くしすぎると無駄なリソースでお金を燃やす羽目に。会社のメインアプリをデプロイした時、妥当だと思った制限値を設定したのに、たった2日後のトラフィック急増時にポッドが次々と強制終了させられたのは忘れられません。監視ダッシュボードはOOM(メモリ不足)エラーでクリスマスツリーみたいに光りまくってました(笑)。
あの事件以降、私は体系的なアプローチを確立しました。まず実際の使用パターンを時間をかけてモニタリングし、requestsはP50(中央値)、limitsはP95(ピーク時)で設定するようにしました。GoldilocksやVertical Pod Autoscaler(VPA)といったツールを使って推奨値を取得することも効果的でしたね。
[改善ポイント] リソース最適化にはPrometheusでPodの実使用率メトリクスを可視化しつつ、VPAで推奨値を生成するのが有効です。加えてコンテナの起動特性(例えばバッチ処理ならBurstable QoSを使うなど)を考慮し、「limitsはrequestsの1.5~2倍」といった経験則も組み合わせると精度が上がります。
Comparison Table:
| 課題 | 詳細 | 解決策 | 学び |
|---|---|---|---|
| リソース管理の難しさ | CPUとメモリの適切なrequests/limits設定が難しい。 | 使用パターンをモニタリングし、P50/P95で設定。GoldilocksやVertical Pod Autoscalerを活用。 | データドリブンなアプローチが重要であること。 |
| ネットワーク問題 | マルチティアアプリの通信失敗。セキュリティグループの設定ミスによる障害。 | 簡易テストポッドで接続性確認、全てのネットワーク構成を文書化。 | クラウドプロバイダーの設定も考慮する必要があること。 |
| ストレージ問題 | レガシーアプリケーション移行時に永続ボリュームでクラッシュやデータ消失発生。 | StatefulSetへの切り替え、liveness probe/readiness probeを細かく設定。バックアッププロセス整備。 | Kubernetesに設計されていないアプリには特別な配慮が必要だと理解したこと。 |
| 運用効率化の重要性 | 初期セットアップではなく効率的な運用が大きな課題になる場合が多い。 | 定期的に監視・調整を行い、環境ごとの違いを明確化することが有効。 | 運用自体も継続的改善していく必要性を実感したこと。 |
| ステートフルとステートレス管理 | Kubernetesは基本的にステートレスだが、現実には異なるシステム要件あり | CAP定理とcgroup v2によるリソース隔離など新たな知識習得 | どこに永続ストレージが必要か見極められるようになったこと |
本番環境でPodが次々と殺される事件から学んだ監視手法
開発環境と本番環境で異なる設定を作成したおかげで、リソース管理はもう勘に頼るものじゃなくなった。データに基づく判断が可能になり、アプリケーションも負荷時にスムーズにスケールするようになったんだ。
ところが次にぶつかった大きな壁が「なぜ何も繋がらないのか?」という問題だった。マルチティア構成のアプリをセットアップしようとしたら、フロントエンドがバックエンドに接続できず、バックエンドはデータベースと通信できず、外部への接続もすべて失敗する状態。YAMLファイルとにらめっこしてサービス定義を何度も確認し、ネットワークポリシーのトラブルシューティングに時間を費やしたある晩、3回チェックした後に気づいた Kubernetes ネットワーキングの黄金法則:「**全部繋がらない時はセキュリティグループの問題**」。原因はKubernetesの設定ではなくクラウドプロバイダーのネットワーク設定にあったんだ。
今ではネットワーク障害時の対処法が体系化されている:
まず簡易テスト用Podで基本接続性を確認し
変数をシステマティックに潰していく(DNS?ファイアウォール?)
※補足として重要なのは、こうした事象には **Kubeletのリソース監視メカニズム**(`memory.available`や`nodefs.inodesFree`といったevictionシグナル)や **OOM Killerの挙動** の理解が必要なケースもある。実際の運用では **Prometheusアラートルールのカスタマイズ**(例:`kube_pod_status_ready != 1` の持続時間閾値設定)や **PDB(PodDisruptionBudget)のminAvailable最適化** といった対策も効果的だ。
フロントエンドとバックエンドが会話できない絶望的な夜
「これってセキュリティグループの問題?それともサービス定義のミス?」と頭を悩ませながら、私は3つ目の教訓を文書化しました。すべてのネットワーク設定を未来のために記録し、接続関係が一目で分かるネットワーク図を作成したんです。今では新しいサービスを立ち上げる時、必要な通信が数日ではなく数分で確立できるようになりました。
そして3番目の試練——ストレージ地獄。Kubernetesでのストレージ管理には本当に泣かされましたよ。ローカルファイルストレージに依存したレガシーアプリケーションを移行していた時のことです。「永続ボリュームを使えば簡単だろう」と高を括っていたら、何時間もしくは数日正常に動作した後、突然クラッシュするわ、データが謎の消滅を遂げるわで...ノード間移動なんて悪夢そのものでした。Istioでトラフィック監視を導入したり、Fluentdのバッファ設定を見直したりと試行錯誤しましたが、CIDR範囲が衝突した時にはkubectl debugコマンドが命綱になったものです。
クラウドプロバイダーのセキュリティグループ設定が犯人だった瞬間
Kubernetesがデフォルトでステートフルなアプリケーションを嫌うってこと、身をもって学んだよ。基本的にすべてが一時的でステートレスであることを求めるけど、現実はそうじゃないんだよね。突破口が見えたのは次の気づきからだった:
まず、Kubernetes向けに設計されていないアプリこそ特別な扱いが必要だと腹をくくったこと。データベースのようなステートフルなワークロードにはDeploymentじゃなくStatefulSetを使うように切り替えて、永続化データのバックアップと復旧プロセスもしっかり整備した。
それから意外と効いたのが、ストレージ関連の問題を早期検知するためのliveness/readinessプローブの追加。今では永続ストレージを使うべきケースと、アプリ自体をクラウドネイティブに再設計すべきタイミングの見極めがつくようになった。
(※参考補足)クラウドプロバイダーのセキュリティグループ設定でも似たような落とし穴があるよね。「ステートフル検査」の挙動差異やAWS/Azure/GCPごとのルール優先順位なんかは、実際にハマってから気づくパターンが多い。Terraformでの自動検証スクリプト作っとけば防げたかも...って後悔した経験ある人もいるんじゃないかな。
永続ストレージを使うたびにデータが消える魔術のような現象
3年前、真夜中の1時。アパートでモニターをぼんやり見つめながら、なぜ自分のKubernetesクラスターが貪欲な怪物のようにリソースを食い尽くすのか悩んでいた頃のことを思い出します。ドキュメントはあたかも簡単そうに見せ、YouTubeのチュートリアルも「すぐできる」と謳っていたのに。それなのに現実は、キャリア選択を疑うほど苦戦する日々——実は私だけじゃなかったんですよね。
今では何千人ものユーザーが利用するプロダクション環境の複数Kubernetesクラスターを管理していますが、道のりは決して平坦ではありませんでした。ここでは誰も教えてくれない「日常的にぶつかるKubernetesの壁」と、どう乗り越えたかを赤裸々に語ります。
最初に直面した大きな問題はセットアップそのものではなく、「効率的な運用」という予想外の難題でした。特にリソースリクエスト設定が思わぬ落とし穴に——StorageClassのReclaimPolicy(Retain/Delete)設定を見落としたり、ノードセレクタの指定ミスで永続ボリュームが消える事態に何度も見舞われました。AWS EBSならAZ縛りの仕組みを理解しておくとか、VolumeSnapshotを使いこなすとか...地味だけど確実に必要な知識ばかりです。
今では何千人ものユーザーが利用するプロダクション環境の複数Kubernetesクラスターを管理していますが、道のりは決して平坦ではありませんでした。ここでは誰も教えてくれない「日常的にぶつかるKubernetesの壁」と、どう乗り越えたかを赤裸々に語ります。
最初に直面した大きな問題はセットアップそのものではなく、「効率的な運用」という予想外の難題でした。特にリソースリクエスト設定が思わぬ落とし穴に——StorageClassのReclaimPolicy(Retain/Delete)設定を見落としたり、ノードセレクタの指定ミスで永続ボリュームが消える事態に何度も見舞われました。AWS EBSならAZ縛りの仕組みを理解しておくとか、VolumeSnapshotを使いこなすとか...地味だけど確実に必要な知識ばかりです。
ステートフルアプリケーションとKubernetesの相性問題との格闘記
「CPUとメモリのrequestsとlimitsを適切に設定すれば大丈夫」ってみんな言うんですよね。でも、誰も教えてくれなかったのが、その「適切な値」を見つけるのが超大な瓶に入ったジェリービーンの数を当てるみたいな難しさだってこと。低く設定しすぎるとトラフィックが増えた瞬間にアプリがクラッシュするし、高くしすぎると無駄なリソースでお金が溶けていく。うちの会社のメインアプリをデプロイした時、まあまあ妥当な値だろうと思って設定したら、2日後のアクセス集中時にポッドが次々に殺されちゃって…監視ダッシュボードはOOMエラーでクリスマスツリーみたいに真っ赤っかでした(笑)。
あの事件以降、私はシステマティックなアプローチを取るようになりました。まず実際の使用パターンを時間をかけてモニタリングし、requestsはP50(中央値)、limitsはP95(ピーク値)で設定。GoldilocksやVertical Pod Autoscalerのようなツールを使った推奨値も参考にしました。
[補足として:ステートフルアプリ運用ではさらに永続ボリューム選定(ローカルSSDとネットワークストレージのレイテンシ比較)やStatefulSet設計(ヘッドレスサービスと安定ネットワークID連携)、データ整合性手法(分散トランザクション実装例)なども考慮が必要です]
StatefulSetを使い始めてから見えたデータベース管理の光
開発環境と本番環境で異なる設定を構築したことで、リソース管理が「勘」ではなくデータドリブンに。アプリケーションの負荷時スケーリングもスムーズにできるようになりました。
「なぜ通信が全部失敗するんだ?」——これがマルチティアアプリ構築時にぶつかった第二の壁でした。フロントエンドがバックエンドに接続できない、バックエンドはデータベースと通信できず、外部へのアクセスも全て遮断される状態。YAMLファイルとにらめっこしてサービス定義を何度も確認し、ネットワークポリシーのトラブルシューティングに明け暮れた日々です。ある晩、三度確認しても解決せず途方に暮れていた時、気付いたんです。「Kubernetesネットワーキングの黄金律」——もし全ての通信が失敗するなら、それはおそらく**セキュリティグループの問題**だと。原因はKubernetes設定ではなくクラウドプロバイダーのネットワーク設定にあったのです。
今ではネットワーク障害時の調査手順が確立されています:
まず簡易テストポッドで基本接続性を確認し
変数を体系的に排除(DNSか?ファイアウォールか?)していく方法です。
死活監視プローブを設定してもまだ何かがクラッシュする理由
「これってセキュリティグループの設定?それともサービス定義の問題?」と首を傾げながら、3つ目の教訓として「全てのネットワーク構成を文書化して将来参照できるようにする」ことを徹底しました。加えて、4つ目に「システム間の接続関係を可視化したネットワーク図を作成」することで、新規サービスの立ち上げ時に必要な接続が数分で完了するようになったんです。以前のように何日もかかることはなくなりました。
そして3番目の苦難——ストレージ問題には本当に手を焼きました。ローカルファイルストレージに強く依存したレガシーアプリケーションをKubernetesに移行する過程で、「永続ボリュームを使えば簡単だろう」と高を括っていたのですが、これが大間違い。アプリケーションは数時間から数日は正常動作するものの、突如クラッシュしたり、データが不可解に消失したり。ノード間でのアプリケーション移動時には特に悲惨な状態になりました。
[補足資料から反映した表現]
このような事態に対処するため、死活監視プローブの初期遅延(initialDelaySeconds)をJavaアプリの起動特性に合わせて調整したり、ネットワーク遅延環境ではfailureThreshold/successThresholdの閾値を緩和するなど、様々なカスタムパラメータを試行錯誤しました。Execプローブを使ってデータベース接続状態を直接検査する方法も効果的でしたね。根本原因究明にはログとメトリクスの相関分析が欠かせませんでした。
3年間の試行錯誤でたどり着いた本番環境運用のベストプラクティス
Kubernetesがデフォルトではステートフルなアプリケーションを好まないって、身をもって学んだよ。基本的にすべてが一時的でステートレスであることを求めるけど、現実のシステムはそうもいかないんだよね。
転機が訪れたのはこんな気づきからだった:
まず、Kubernetes向けに設計されていないアプリケーションには特別な配慮が必要だと腹をくくったこと。データベースのようなステートフルなワークロードにはDeploymentじゃなくStatefulSetを使うように切り替えたら、途端に挙動が安定し始めた。それから、永続データのバックアップと復旧プロセスを本格的に整備したのも大きかった。ストレージ関連の問題を早期検知できるよう、liveness probeとreadiness probeを細かく設定したのも功を奏してる。
今では「ここは永続ストレージが必要なケース」と「クラウドネイティブにリファクタリングすべき箇所」の見極めがつくようになった。まさに「何がクラッシュしてるのか」と頭を抱える日々から脱却できた感じだね。
(技術的補足として)分散システムのCAP定理に基づいた可用性設計や、cgroup v2を使ったリソース隔離のノウハウも徐々に蓄積されてきた。HPAの閾値最適化とか、スポットインスタンスとオンデマンドの混在比率なんかも試行錯誤しながら調整している最中だ。
転機が訪れたのはこんな気づきからだった:
まず、Kubernetes向けに設計されていないアプリケーションには特別な配慮が必要だと腹をくくったこと。データベースのようなステートフルなワークロードにはDeploymentじゃなくStatefulSetを使うように切り替えたら、途端に挙動が安定し始めた。それから、永続データのバックアップと復旧プロセスを本格的に整備したのも大きかった。ストレージ関連の問題を早期検知できるよう、liveness probeとreadiness probeを細かく設定したのも功を奏してる。
今では「ここは永続ストレージが必要なケース」と「クラウドネイティブにリファクタリングすべき箇所」の見極めがつくようになった。まさに「何がクラッシュしてるのか」と頭を抱える日々から脱却できた感じだね。
(技術的補足として)分散システムのCAP定理に基づいた可用性設計や、cgroup v2を使ったリソース隔離のノウハウも徐々に蓄積されてきた。HPAの閾値最適化とか、スポットインスタンスとオンデマンドの混在比率なんかも試行錯誤しながら調整している最中だ。


