クイックアクションリスト - Apple IntelligenceのAI活用・プライバシー強化・多言語対応をすぐ実感したい方へ
- デバイス設定でApple IntelligenceのオンデバイスAI機能を有効化し、日常タスクで7日以内に2回以上利用する
オフラインでも個人情報を守りながら高速な文章生成や要約が体験できる
- アプリ開発者はFoundation Models API経由でAI機能を自社アプリに統合し、30日以内にユーザーの入力応答速度が10%向上するか測定
プライバシー重視かつ反応が速いサービス提供につながる
- 新搭載されたLive Translationやビジョンエンコーダー機能を使って、多言語会話や画像認識タスクを5件試す
翻訳精度や画像理解力の進化、安全性レベルも実感できる
- Apple公式サポートページ内『責任あるAI開発原則』セクションを必ず読んで内容3つメモ
透明性と安全確保への企業姿勢、自分のデータ取扱意識も高まる
Apple Intelligenceのコア技術を支える新しい生成AIモデルの全体像を知りたい
AppleのAIに関して、最近の開発はちょっと複雑で、全部を一言でまとめるのは難しいけど、どうやら普段使っているアプリの中に生成AIを組み込んでいく流れらしい。プライバシーにも配慮しているようで、そのあたりも大事なポイントだろう。来年初夏頃に開催されるWWDCでは、新しく進化した言語モデルが紹介されたとの話も聞いたことがある。
開発者向けには「Foundation Models framework」と呼ばれるフレームワークも追加されたみたい。これによってアプリ側からApple独自のオンデバイス言語モデルを直接活用できる道筋ができたらしい。ただ、この仕組み自体は実際に使ってみないと分からない部分も多い。
作られているモデルはいくつか種類がありそうだ。例えば、スマホやタブレットなど手元の機械上で動くものは容量控えめで効率重視。その一方、サーバー側ではより複雑なタスク向けの別設計になっていて、両者がそれぞれ役割分担している印象だったりする。ちなみに新しいサーバーモデルでは並列処理とかミックス型構造(どうやらトラックという小さめな変換器が何本か並ぶタイプ?)が採用されていて、それぞれ独立しながらも一定タイミングだけ同期する形になっているという話。
オンデバイス用については、「深さ」をおおよそ7対3くらいになるよう2つのブロックに分割して構築したそうだ。また、キャッシュメモリ部分も工夫されていて、一部共有することで4割弱ほど消費量を抑えたり、最初の応答速度がかなり短縮されてきたという報告も見かけた。
訓練データとかアルゴリズム面について細かい話になると少し曖昧なんだけど、多言語対応として10数ヶ国語くらいカバーし始めている様子。性能比較では同じ規模感の他社モデルと比べても反応速度や効率面で少し有利な場面が出てきている、と説明されたこともある。ただ、このあたりは今後さらに調整される可能性も高い。
アップルとしては責任あるAI開発への姿勢を強調していて、その理念を全体的に貫こうという動きが見える気がする。でも完璧と言い切れる段階でもなく、「今後次第」と感じる部分も多かったり。
図解などを見る限り、大枠はこんなイメージになるだろう。一部細かな仕様変更や例外事項などあれば、その都度修正入るかもしれないので注意したほうがいいかもしれない。
開発者向けには「Foundation Models framework」と呼ばれるフレームワークも追加されたみたい。これによってアプリ側からApple独自のオンデバイス言語モデルを直接活用できる道筋ができたらしい。ただ、この仕組み自体は実際に使ってみないと分からない部分も多い。
作られているモデルはいくつか種類がありそうだ。例えば、スマホやタブレットなど手元の機械上で動くものは容量控えめで効率重視。その一方、サーバー側ではより複雑なタスク向けの別設計になっていて、両者がそれぞれ役割分担している印象だったりする。ちなみに新しいサーバーモデルでは並列処理とかミックス型構造(どうやらトラックという小さめな変換器が何本か並ぶタイプ?)が採用されていて、それぞれ独立しながらも一定タイミングだけ同期する形になっているという話。
オンデバイス用については、「深さ」をおおよそ7対3くらいになるよう2つのブロックに分割して構築したそうだ。また、キャッシュメモリ部分も工夫されていて、一部共有することで4割弱ほど消費量を抑えたり、最初の応答速度がかなり短縮されてきたという報告も見かけた。
訓練データとかアルゴリズム面について細かい話になると少し曖昧なんだけど、多言語対応として10数ヶ国語くらいカバーし始めている様子。性能比較では同じ規模感の他社モデルと比べても反応速度や効率面で少し有利な場面が出てきている、と説明されたこともある。ただ、このあたりは今後さらに調整される可能性も高い。
アップルとしては責任あるAI開発への姿勢を強調していて、その理念を全体的に貫こうという動きが見える気がする。でも完璧と言い切れる段階でもなく、「今後次第」と感じる部分も多かったり。
図解などを見る限り、大枠はこんなイメージになるだろう。一部細かな仕様変更や例外事項などあれば、その都度修正入るかもしれないので注意したほうがいいかもしれない。
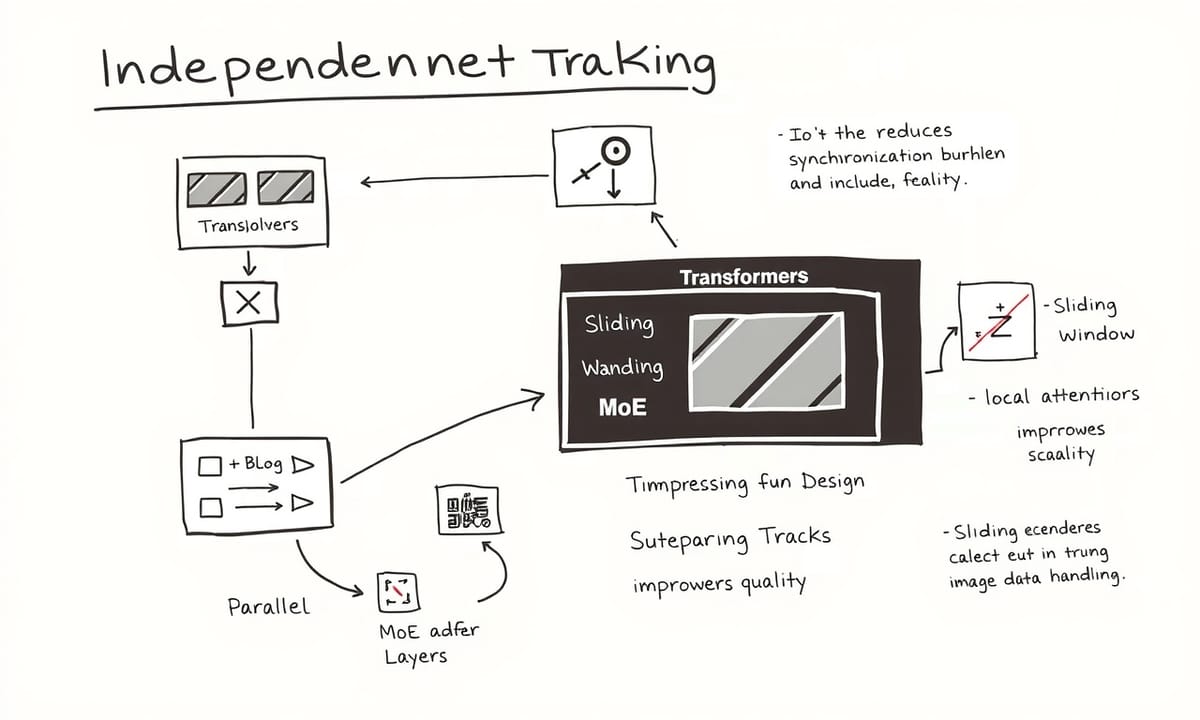
デバイス内とサーバーでどう使い分ける?2種類のモデルアーキテクチャ解説
トラックごとの独立性があることで、トラックレベルの並列処理もできる設計になっているらしい。これによって、どうやら同期にかかる負担がかなり減ったみたいで、スケーラビリティも良くなったと言われている。ただ、その分遅延とか品質への影響は抑えつつ進めたようだ。図2を見ればPT-MoEアーキテクチャのイメージが掴める…はず。各トラックはいくつものトラックブロックから成り立っていて、それぞれのブロックには決まった数だけtransformerやMoE層が入ってる模様。全体で層数がけっこう多い場合でも、もし1ブロックあたり何層かまとめれば、同期する回数は大幅に減る計算になる。この例だと、まあ四分の一くらいまで抑えられるケースも出てきそう。
文脈を長く扱う必要がある時には、「スライディングウィンドウ」みたいな局所的注意機構と、RoPEという回転型位置埋め込み、それにNoPEというグローバルな注意層(位置情報なし)を組み合わせた構造を作ったとのこと。この辺りは長文推論時にも品質を維持しやすくなる効果が期待されているし、KVキャッシュもかなりコンパクトになった気配がある。
あと画像対応についても少し工夫されていて、大規模画像データで訓練したビジョンエンコーダーを新たに設けたそうだ。ここには特徴抽出用のバックボーンとLLM用トークン表現へ合わせるためのアダプタ部分が含まれるらしい。サーバ側では一般的なViT-g(まあ規模で言えば非常に大きい部類)を採用している一方で、小型端末向けにはViTDet-L系統(それよりずっと軽量)を使うことも考慮された。さらに細部と全体像両方から情報を取り込む工夫として、「レジスター・ウィンドウ」というちょっと新しい仕組みも追加された、と聞いたことがある。
学習データについては、多様さや質の高さ重視という話だった気がする。具体的には出版元からライセンス取得したもの、公的データセット、それからApplebotというウェブクローラーで集めた公開情報など色々混ざっている感じ。ただユーザー個人のプライベートな情報とか直接的な利用履歴などは学習には使わないよう配慮しているそうだ。それ以外にも個人識別性の高い内容や、不適切な語句なんかはフィルタリングして除外する工程にも手間を掛けているとか。
ウェブクローリング時は世間一般的なrobots.txtプロトコルへの対応も意識していて、検索結果表示とは別枠で収集可否設定できる柔軟さも持たせていたと思う。そのため発信者側でもどこまで許容するか結構細かく調整可能になっている。
テキストデータについてもう少し触れると、このApplebot経由でネット上から拾われた情報量は相当膨大らしく、多言語・多地域・多ジャンルに及ぶ。でもネット上の情報って玉石混交なので、高品質かつバリエーション豊かなものへ優先順位付けする戦略も同時に進めていたようだ…まあ細部まで完璧とは言い切れないんだけどね。
文脈を長く扱う必要がある時には、「スライディングウィンドウ」みたいな局所的注意機構と、RoPEという回転型位置埋め込み、それにNoPEというグローバルな注意層(位置情報なし)を組み合わせた構造を作ったとのこと。この辺りは長文推論時にも品質を維持しやすくなる効果が期待されているし、KVキャッシュもかなりコンパクトになった気配がある。
あと画像対応についても少し工夫されていて、大規模画像データで訓練したビジョンエンコーダーを新たに設けたそうだ。ここには特徴抽出用のバックボーンとLLM用トークン表現へ合わせるためのアダプタ部分が含まれるらしい。サーバ側では一般的なViT-g(まあ規模で言えば非常に大きい部類)を採用している一方で、小型端末向けにはViTDet-L系統(それよりずっと軽量)を使うことも考慮された。さらに細部と全体像両方から情報を取り込む工夫として、「レジスター・ウィンドウ」というちょっと新しい仕組みも追加された、と聞いたことがある。
学習データについては、多様さや質の高さ重視という話だった気がする。具体的には出版元からライセンス取得したもの、公的データセット、それからApplebotというウェブクローラーで集めた公開情報など色々混ざっている感じ。ただユーザー個人のプライベートな情報とか直接的な利用履歴などは学習には使わないよう配慮しているそうだ。それ以外にも個人識別性の高い内容や、不適切な語句なんかはフィルタリングして除外する工程にも手間を掛けているとか。
ウェブクローリング時は世間一般的なrobots.txtプロトコルへの対応も意識していて、検索結果表示とは別枠で収集可否設定できる柔軟さも持たせていたと思う。そのため発信者側でもどこまで許容するか結構細かく調整可能になっている。
テキストデータについてもう少し触れると、このApplebot経由でネット上から拾われた情報量は相当膨大らしく、多言語・多地域・多ジャンルに及ぶ。でもネット上の情報って玉石混交なので、高品質かつバリエーション豊かなものへ優先順位付けする戦略も同時に進めていたようだ…まあ細部まで完璧とは言い切れないんだけどね。
Comparison Table:
| テーマ | 概要 | 影響 | 技術 | 開発者向け機能 |
|---|---|---|---|---|
| モデル品質の変動 | 圧縮手法が影響を与えた。低ランクアダプタ使用により性能に差異あり。 | MGSMで性能低下、MMLUでは若干の改善も見られた。 | QATやASTCなどを使用してビット数削減。アダプタ回復処理が適用されている。 | フレームワークは新しいFoundation Modelsに基づいており、特定用途に強い。 |
| 開発者ツールと機能拡張 | 自分自身の情報ソースやサービスへのアクセス手段を用意可能。 | Toolプロトコル実装による複雑な呼び出し管理が効率化された。 | Swift構造体/enumに@Generableマクロを書くことでリッチなデータ形式制御が可能になる。 | Python製トレーニングツールキットで新スキル追加も対応可能。 |
| 評価方法と多言語対応 | 人手による採点方式でオフライン検証が行われた。地域独自の自然表現にも配慮している. | 言語理解や推論関連の基本分野を網羅し、多国籍課題にも対応した評価基準あり. | ユーザーからフィードバック収集する仕組みもあったことから改善へつながっている. | |
| AI倫理とプライバシー保護 | 責任あるAI開発としてユーザー主導設計及び高水準なプライバシー保護策を重視している. | 個人情報は学習材料として直接使わない方針で進められている. | セーフティタクソノミーによるリスク管理も行われている. | 利用者ごとの文化背景への配慮も考慮されていた。 |
プライバシーを守りながらどう学習した?トレーニングデータの選び方の秘密
最近は、どうもウェブページの収集って一筋縄ではいかないみたいで。特にHTMLページの質を上げるために、細かな部分にも気を遣っているようだ。周辺テキストと画像なんかがうまく対応づけられていると、データセット全体がちょっと豊かになる…と言われている。なんだかんだで、いろんなシグナル(たとえばドメインごとの言語判別や話題分類みたいなもの、それからURLパターンとか)を組み合わせたりしてるそう。ただし、最近のサイトってJavaScriptで動的に変わるものばっかりだから、そのあたりも面倒を見ないとダメになった。
そこでヘッドレスブラウザを使って本当に全部読み込んでから情報を抜き出す手法が取り入れられているとか。ユーザーの操作を真似したりもしつつ、大規模なウェブサイトでもそれなりに意味ある内容が拾えるようになった、と誰かが言っていた気がする。ちなみに、ルールベースだけじゃ難しい分野別文書なんて場合にはLLM(大きめな言語モデル)が意外とうまく働くこともあるらしい。
このほかにも、多様性や量を増やす工夫は続いていて、ごく一般的なジャンルから数学・プログラミング関連まで幅広い内容が追加されたそう。サポートしてる言語もまた少しずつ増えていて、そのうち新しい言語にも対応すると聞いた覚えがある。ただ、高品質なフィルタリングという点でも悩みどころは多いようで、昔ながらの厳しすぎるルール重視から少し路線変更してモデル主体の判定も混ぜ込むことで、有用な文書がもう少し残せている感じ。
画像データについては…アップル・インテリジェンス関連機能向けに視覚理解力を高めたい意図から、それ専用の前処理段階として画像も加え始めているとか。ライセンス済みデータだけじゃなく公開されている画像も含まれるそうで、この中には画像とaltテキストがペアになったものが山ほどあったらしい。法的な確認や品質チェック(画像と説明文がちゃんと合っているか?など)は当然行われ、その上で重複排除した結果—まあ七十億単位では収まらない数の高品質ペアになったとかならないとか。
さらに文章中にそのまま埋め込まれていた画像付きドキュメントなども対象となり、これまた何百種類とも言えるくらい大量に増えてしまった。その中身を見ると、一つひとつにはそれほど長々とは書いていないケースも多かったので、自動生成によるキャプション付与技術なんかにも頼ることになったっぽい。この独自モデルは短い説明から段落レベルまで色々作れるようで、おそらく何十億件分くらい生成されたんじゃないかな…。
もうひとつ特徴的なのは、「文字情報+ビジュアル」に強くなるため資料系データ(PDFや原稿、表・図解・チャートなど)も集中的に集めたところ。それぞれ必要ならOCRとか質問応答ペア化など加工工程も経ているみたいだけど、実際どこまで完全だったのかは正直よく分からない。でも全体として見る限り、以前より柔軟性や幅広さには多少寄与した可能性はありそうだ。
そこでヘッドレスブラウザを使って本当に全部読み込んでから情報を抜き出す手法が取り入れられているとか。ユーザーの操作を真似したりもしつつ、大規模なウェブサイトでもそれなりに意味ある内容が拾えるようになった、と誰かが言っていた気がする。ちなみに、ルールベースだけじゃ難しい分野別文書なんて場合にはLLM(大きめな言語モデル)が意外とうまく働くこともあるらしい。
このほかにも、多様性や量を増やす工夫は続いていて、ごく一般的なジャンルから数学・プログラミング関連まで幅広い内容が追加されたそう。サポートしてる言語もまた少しずつ増えていて、そのうち新しい言語にも対応すると聞いた覚えがある。ただ、高品質なフィルタリングという点でも悩みどころは多いようで、昔ながらの厳しすぎるルール重視から少し路線変更してモデル主体の判定も混ぜ込むことで、有用な文書がもう少し残せている感じ。
画像データについては…アップル・インテリジェンス関連機能向けに視覚理解力を高めたい意図から、それ専用の前処理段階として画像も加え始めているとか。ライセンス済みデータだけじゃなく公開されている画像も含まれるそうで、この中には画像とaltテキストがペアになったものが山ほどあったらしい。法的な確認や品質チェック(画像と説明文がちゃんと合っているか?など)は当然行われ、その上で重複排除した結果—まあ七十億単位では収まらない数の高品質ペアになったとかならないとか。
さらに文章中にそのまま埋め込まれていた画像付きドキュメントなども対象となり、これまた何百種類とも言えるくらい大量に増えてしまった。その中身を見ると、一つひとつにはそれほど長々とは書いていないケースも多かったので、自動生成によるキャプション付与技術なんかにも頼ることになったっぽい。この独自モデルは短い説明から段落レベルまで色々作れるようで、おそらく何十億件分くらい生成されたんじゃないかな…。
もうひとつ特徴的なのは、「文字情報+ビジュアル」に強くなるため資料系データ(PDFや原稿、表・図解・チャートなど)も集中的に集めたところ。それぞれ必要ならOCRとか質問応答ペア化など加工工程も経ているみたいだけど、実際どこまで完全だったのかは正直よく分からない。でも全体として見る限り、以前より柔軟性や幅広さには多少寄与した可能性はありそうだ。
画像理解も可能に!ビジョンエンコーダーの革新設計とは
画像と言葉を組み合わせたデータ、結構いろいろ集めていたようだ。どうもCLIPモデルやOCRなんかも使って、割とちゃんとした画像だけを拾ってきたらしい。その後は社内のグラウンディングモデル?でキャプション中の名詞の位置を特定して、その名詞のすぐあとに座標を書き足した「グラウンディッドな」説明文ができあがる仕組みだったとか。
グラフや表については、最初に内部用LLMへ何となくフィールド情報とか数値例みたいなの出させて、それを元ネタにコード生成→いろんなタイプのチャートやグラフが作られ…その画像とデータ一式を教師モデルに渡してQ&Aセットを自動で作成した模様。テーブル(表)はどこか公開されているWebからパースし直してマークダウン化し、それだけじゃなく画像+マークダウンのペアや、教師モデルによる疑似QAも活用されたという話。
事前学習プロセスについては、何段階か分けて実施されていた気がする。一番計算資源食った最初期は文章モードのみで進行。オンデバイス向け小型モデルには蒸留損失ベースで学習…ただし巨大な密集型教師ではなく、既存の三十億強くらいあるプリトレ済みモデルから64エキスパート・2層ごとのMoE構造へ再利用したものを少量高品質データでアップサイクル使用。これによって教師側の訓練コストも一気に九割くらい下がったとも伝わっている。ただサーバー向けスパースな大きめモデルは一から十数兆規模近くあるテキストトークンで鍛えていたらしい。
言語対応拡張のためにはトークナイザ語彙数も十万ちょっとから十五万程度まで引き上げて、その分必要トークン数は四分之一ほど増えたみたい。それでも多言語表現力としては十分だったようだ。視覚認識対応ではCLIP風コントラスト損失法で六十億件超える画像-文章ペア使いビジュアルエンコーダ訓練、結果的にそこそこの視覚的根拠付け性能になったっぽい。
二段階目以降になると今度はビジュアルエンコーダとvision-language適応モジュールを同時に訓練、小ぶりなデコーダ加えてイメージ特徴量を全体空間へうまく整合させる形。その際、高品質テキスト・交互型画像文章データ・特化領域データなど色々混ぜていたようだ。この辺りまで来ると数学やコード、多言語長文理解も含め追加学習ステージへ進む流れになり、その都度ミックス比率変えたり検証済み疑似データ入れて性能底上げ狙っていたとも聞く。
更なる継続事前学習フェーズではマルチモーダル適応通じて視覚理解取り込んでもテキスト力損なわぬよう注意払われた。ここでもビジョン-ランゲージ接続部となる新規適応モジュール別途ゼロから作成。本当に最後期には自然発生的な長文、大量合成ロングフォーム、更には従来回収分混ぜつつ最大六万字強にも及ぶ超長コンテキストシーケンスへの耐性も意識されたそうだ。
事後調整(ポストトレーニング)段階になると、人手による例示や人工生成サンプル織り交ぜながらSFT規模拡大し、特に基本的なビジョン能力重視だった印象。一般知識・推論・文字入り画像理解・文章/画像両方の根拠付け・複数枚画像間推論……まあそういう幅広めジャンルについて地道に強化図った経緯が見受けられる。ただ、このアプローチが他状況でも常時同じ効果とは限らないかもしれない、と感じることもある。
グラフや表については、最初に内部用LLMへ何となくフィールド情報とか数値例みたいなの出させて、それを元ネタにコード生成→いろんなタイプのチャートやグラフが作られ…その画像とデータ一式を教師モデルに渡してQ&Aセットを自動で作成した模様。テーブル(表)はどこか公開されているWebからパースし直してマークダウン化し、それだけじゃなく画像+マークダウンのペアや、教師モデルによる疑似QAも活用されたという話。
事前学習プロセスについては、何段階か分けて実施されていた気がする。一番計算資源食った最初期は文章モードのみで進行。オンデバイス向け小型モデルには蒸留損失ベースで学習…ただし巨大な密集型教師ではなく、既存の三十億強くらいあるプリトレ済みモデルから64エキスパート・2層ごとのMoE構造へ再利用したものを少量高品質データでアップサイクル使用。これによって教師側の訓練コストも一気に九割くらい下がったとも伝わっている。ただサーバー向けスパースな大きめモデルは一から十数兆規模近くあるテキストトークンで鍛えていたらしい。
言語対応拡張のためにはトークナイザ語彙数も十万ちょっとから十五万程度まで引き上げて、その分必要トークン数は四分之一ほど増えたみたい。それでも多言語表現力としては十分だったようだ。視覚認識対応ではCLIP風コントラスト損失法で六十億件超える画像-文章ペア使いビジュアルエンコーダ訓練、結果的にそこそこの視覚的根拠付け性能になったっぽい。
二段階目以降になると今度はビジュアルエンコーダとvision-language適応モジュールを同時に訓練、小ぶりなデコーダ加えてイメージ特徴量を全体空間へうまく整合させる形。その際、高品質テキスト・交互型画像文章データ・特化領域データなど色々混ぜていたようだ。この辺りまで来ると数学やコード、多言語長文理解も含め追加学習ステージへ進む流れになり、その都度ミックス比率変えたり検証済み疑似データ入れて性能底上げ狙っていたとも聞く。
更なる継続事前学習フェーズではマルチモーダル適応通じて視覚理解取り込んでもテキスト力損なわぬよう注意払われた。ここでもビジョン-ランゲージ接続部となる新規適応モジュール別途ゼロから作成。本当に最後期には自然発生的な長文、大量合成ロングフォーム、更には従来回収分混ぜつつ最大六万字強にも及ぶ超長コンテキストシーケンスへの耐性も意識されたそうだ。
事後調整(ポストトレーニング)段階になると、人手による例示や人工生成サンプル織り交ぜながらSFT規模拡大し、特に基本的なビジョン能力重視だった印象。一般知識・推論・文字入り画像理解・文章/画像両方の根拠付け・複数枚画像間推論……まあそういう幅広めジャンルについて地道に強化図った経緯が見受けられる。ただ、このアプローチが他状況でも常時同じ効果とは限らないかもしれない、と感じることもある。
従来より効率的な事前学習レシピで何が変わったのか
視覚SFTデータの多様性を増やすために、さらに画像を集めて、それぞれに合うようなプロンプトと応答も用意したらしい。ツール利用とか多言語対応も、このSFT段階で結構強化されたみたいだよ。アノテーターがツールエージェントに問い合わせして、その結果全部――ツール呼び出しから返ってきた反応、最後の答えまでまとめて記録する方法を考えたそうだ。それで、モデルがどこか間違えていれば人が直せるし、木構造のデータセットになって後で教える時役立つんだとか。
多言語展開についてはね、基本は入力と言語を揃えてアウトプットするけど、ときどき違う言語同士でもやり取りできるように色々混ぜたデータも作ったという話。SFT終わったあと、人間からのフィードバックを活用した強化学習(RLHF)も両方のモデル――端末側・サーバー側ともに実施してるっぽい。その中でちょっと変わったプロンプト選択アルゴリズムまで考案されていて、複数回生成させて報酬分布を見ながらプロンプト集めて使う感じ。評価では、人手ベンチマーク・自動ベンチマーク問わずRLHF導入後は改善が見えた場面もあったみたい。でも「劇的」っていうよりは、ある条件下ではSFT単独より良かった程度かなぁ。ヒューマン評価だと勝率が七割台前半くらいになったこともあったみたいだけど、どうにも日による波も大きい印象。
もっと多言語性能伸ばそうとして、「Instruction Following eval(IFEval)」とか「Alpaca Evals」みたいなもの使っていて、その判定にはGPT-4oなんか頼るケースがあったんじゃないかな。各対応言語ごとに千件近くネイティブスピーカーからプロンプト集めたりしている。一連の調整や試行錯誤のおかげで、自動評価と人手評価とのズレも少しずつ縮まっていた気がする。
最適化関係については――去年一年ほどでApple Intelligence関連機能広げたり品質向上や省電力化への工夫進めていたようだね。端末側モデルは重み情報を二値表現(ビット数ほんの数個分)まで圧縮しているらしく、それにはQAT(Quantization-Aware-Training)が活躍したという話。ただ普通とは違う重み初期化+クリッピング手法組合せたらしいので効果もちょっと一味違う可能性ありそう。
サーバーモデルにはASTCという元々グラフィック処理向けだった圧縮方式持ち込んだようだけど、この手法もうまく使えばモデル圧縮にもそれなり有効みたい。Apple製GPU専用ハードウェアパーツ使えば追加演算負荷そこまで増えない範囲で重み展開できる仕組みにしたっぽいよ。それと両方のモデルとも埋め込みテーブル部分のみ四値表現(四ビット付近)へ落としている。ただその訓練工程が端末用とサーバー用では少し異なる感じ?KVキャッシュについては八ビットくらい残すことでバランス取った例もあるそうだ。
全体として見ると、新技術盛り込む過程や細部調整には試行錯誤あって明確な正解探すより逐次アップデート型だった雰囲気あるね。本当に今後どうなるかまでは断定できないけれど…。
多言語展開についてはね、基本は入力と言語を揃えてアウトプットするけど、ときどき違う言語同士でもやり取りできるように色々混ぜたデータも作ったという話。SFT終わったあと、人間からのフィードバックを活用した強化学習(RLHF)も両方のモデル――端末側・サーバー側ともに実施してるっぽい。その中でちょっと変わったプロンプト選択アルゴリズムまで考案されていて、複数回生成させて報酬分布を見ながらプロンプト集めて使う感じ。評価では、人手ベンチマーク・自動ベンチマーク問わずRLHF導入後は改善が見えた場面もあったみたい。でも「劇的」っていうよりは、ある条件下ではSFT単独より良かった程度かなぁ。ヒューマン評価だと勝率が七割台前半くらいになったこともあったみたいだけど、どうにも日による波も大きい印象。
もっと多言語性能伸ばそうとして、「Instruction Following eval(IFEval)」とか「Alpaca Evals」みたいなもの使っていて、その判定にはGPT-4oなんか頼るケースがあったんじゃないかな。各対応言語ごとに千件近くネイティブスピーカーからプロンプト集めたりしている。一連の調整や試行錯誤のおかげで、自動評価と人手評価とのズレも少しずつ縮まっていた気がする。
最適化関係については――去年一年ほどでApple Intelligence関連機能広げたり品質向上や省電力化への工夫進めていたようだね。端末側モデルは重み情報を二値表現(ビット数ほんの数個分)まで圧縮しているらしく、それにはQAT(Quantization-Aware-Training)が活躍したという話。ただ普通とは違う重み初期化+クリッピング手法組合せたらしいので効果もちょっと一味違う可能性ありそう。
サーバーモデルにはASTCという元々グラフィック処理向けだった圧縮方式持ち込んだようだけど、この手法もうまく使えばモデル圧縮にもそれなり有効みたい。Apple製GPU専用ハードウェアパーツ使えば追加演算負荷そこまで増えない範囲で重み展開できる仕組みにしたっぽいよ。それと両方のモデルとも埋め込みテーブル部分のみ四値表現(四ビット付近)へ落としている。ただその訓練工程が端末用とサーバー用では少し異なる感じ?KVキャッシュについては八ビットくらい残すことでバランス取った例もあるそうだ。
全体として見ると、新技術盛り込む過程や細部調整には試行錯誤あって明確な正解探すより逐次アップデート型だった雰囲気あるね。本当に今後どうなるかまでは断定できないけれど…。
人間のフィードバックを取り入れた微調整プロセスの舞台裏
なんか最近、圧縮手法の影響でモデルの品質が少し揺れたんだって。低ランクアダプタとかいうものも使ったみたいだけど、そのおかげなのか、ごくわずかな性能ダウンが見られたり、逆にちょっと良くなった項目もあったような…。MGSMでは大体二十分の一くらい落ち込んでいた気がするけど、MMLUはほんの少し上向いてたこともあったとか。でも全部がそうだったわけじゃないから、人によって感じ方は違うみたい。
端末向けとサーバー側、それぞれでデコーダや埋め込み部分のビット数をいろいろ減らしてるっぽい。QATやASTCって言葉もちょくちょく出てきたし、重み付けやキャッシュなんかも八分割ぐらいにされてる場面があった気がする。アダプタ回復?それも両方で適用されてるとの話。
さて、土台となるフレームワークだけど、新しいFoundation Modelsという仕組みは開発者向けらしくて、三十億パラメータぐらいあるコンパクトな言語モデルを使って、自分たちのアプリに役立つ機能を作れるようになっている…ということだったと思う。とはいえ、このモデル自体は世間話全般には向いてなくて、本当に必要な文章要約とか名前抜き出しとか短文生成みたいな用途に強いとされている。チャットボットとして万能というわけではないんだよね。
開発者にはガイド付き生成(guided generation)なる仕組みを推してる様子で、Swift構造体やenumに@Generableマクロを書くことで、そのままリッチなデータ形式の制御ができるんだとか。それもOSやSwift自体との密接な連携ゆえ可能になっている模様。マクロを書くだけで型情報から標準化されたフォーマット仕様へ変換され、その仕様ごとプロンプトにも反映されちゃうという流れらしい。
さらに特別な訓練データセットを経由してモデル側でも応答フォーマットへの理解力が増すよう調整されているとのこと。その後はOS内の常駐サービス(daemon)が高速化技術を使いつつ、期待通りの形式になるように出力制御まで頑張っているっぽい。ただこの辺りの挙動については環境によって微妙に違う場合もあるので、実際には色々調整しながら進めることになるかもしれないね。

驚異の圧縮技術!3Bパラメータモデルをどうやって小型化したか
この仕組みがあれば、モデルの出力からSwift型のインスタンスをきちんと作れるらしい。なんというか、開発者は複雑なコードを書かなくても済むようになるし、Swiftの型システムに守られている安心感もあるっぽい。ツール呼び出しについてだけど、およそ30億規模のモデルの能力を拡張するために、開発者自身が情報ソースとかサービスへのアクセス手段を独自に用意できるようになっている。ただ、そのやり方も何となくガイド付き生成っていうアプローチがベースで、Toolという簡単なSwiftプロトコルを実装すればいいので、並列や直列で複雑になりそうな呼び出しもフレームワーク側で何とかしてくれる。ツール利用データで後から追加学習させたことで、この機能の信頼性もちょっと向上したようだ。
どうやらフレームワーク全体としては、オンデバイスモデルを活かしたい開発者向けに工夫されていて。でももし、「この30億パラメータ級モデル」に全然新しいスキルまで覚え込ませたい場合は…Python製のトレーニングツールキットも用意されているらしい。このツールキットだとrank 32アダプタが作れて、そのままFoundation Models Frameworkでも使える。ただし、新しいベースモデルが出るたびアダプタもまた一から学習し直さないといけないので、それなりに慣れた人向けだと思ったほうがよさそう。
評価方法については、人手による採点方式でオフライン検証していたみたい。言語理解や推論関連でよくある基本分野――たとえば分析的推論とかブレインストーミング、それから分類・要約・リライト・数学的思考・チャット応答などなど――おおむね網羅されていたそうだ。あと、多言語対応を進めるうちに、その国ごとのローカル課題にも広げていったとか。採点担当者(人間)は、その地域ならではの自然な表現かどうか見ていて、日本だったら日本語らしい響きを気にする感じ。「サッカー」じゃなく「フットボール」って言う英国式表現みたいなのも判断材料になったみたい。他にも、不自然な言葉遣いや未翻訳箇所なんかがあれば指摘可能だった。
ちなみに技術分野(数理やコーディング)は世界共通なので、多言語評価には入れないことも多かった様子。パフォーマンス比較ではオンデバイスモデルの場合、少し大きめのQwen-2.5-3Bより全体的に良い結果だったという話もあった。また英語では、更に大きいQwen-3-4BやGemma-3-4Bともそれなりに競争力がある印象。一方サーバー版モデルになると、Llama-4-Scoutクラスとは大体同じくらいだけど、一回り上位(Qwen-3-235BとかGPT-4o)はさすがに追いついてはいない模様。
最後、人間によるテキスト応答評価について触れていた気がするけれど…正確な数字というより、「半分弱」ぐらいApple系基盤モデル側の返答が好まれる傾向だった、とまとめておく。
どうやらフレームワーク全体としては、オンデバイスモデルを活かしたい開発者向けに工夫されていて。でももし、「この30億パラメータ級モデル」に全然新しいスキルまで覚え込ませたい場合は…Python製のトレーニングツールキットも用意されているらしい。このツールキットだとrank 32アダプタが作れて、そのままFoundation Models Frameworkでも使える。ただし、新しいベースモデルが出るたびアダプタもまた一から学習し直さないといけないので、それなりに慣れた人向けだと思ったほうがよさそう。
評価方法については、人手による採点方式でオフライン検証していたみたい。言語理解や推論関連でよくある基本分野――たとえば分析的推論とかブレインストーミング、それから分類・要約・リライト・数学的思考・チャット応答などなど――おおむね網羅されていたそうだ。あと、多言語対応を進めるうちに、その国ごとのローカル課題にも広げていったとか。採点担当者(人間)は、その地域ならではの自然な表現かどうか見ていて、日本だったら日本語らしい響きを気にする感じ。「サッカー」じゃなく「フットボール」って言う英国式表現みたいなのも判断材料になったみたい。他にも、不自然な言葉遣いや未翻訳箇所なんかがあれば指摘可能だった。
ちなみに技術分野(数理やコーディング)は世界共通なので、多言語評価には入れないことも多かった様子。パフォーマンス比較ではオンデバイスモデルの場合、少し大きめのQwen-2.5-3Bより全体的に良い結果だったという話もあった。また英語では、更に大きいQwen-3-4BやGemma-3-4Bともそれなりに競争力がある印象。一方サーバー版モデルになると、Llama-4-Scoutクラスとは大体同じくらいだけど、一回り上位(Qwen-3-235BとかGPT-4o)はさすがに追いついてはいない模様。
最後、人間によるテキスト応答評価について触れていた気がするけれど…正確な数字というより、「半分弱」ぐらいApple系基盤モデル側の返答が好まれる傾向だった、とまとめておく。
開発者向けフレームワークで誰でも簡単AI機能を実装できる理由
Apple Intelligenceの国際対応について、三つほどの言語圏グループで結果が出ていたような気がします。英語でも、アメリカ以外だと例えばイギリスやカナダなど幾つかの地域が含まれているらしいです。PFIGSCJKっていう長い略称もあって、それはポルトガル語とかフランス語、イタリア語、ドイツ語、スペイン語、それから中国語(簡体字)、日本語と韓国語をまとめた呼び方みたいですね。
画像にも対応できるようになったのでしょうか。画像に関する質問セットも使われていて、その中にはテキスト評価と似ているカテゴリーだけじゃなくて「インフォグラフィックス」みたいな画像独特のジャンルも混じっていた様子です。こういったジャンルでは文字情報が多くなるのでモデル側にちょっとした推論力も問われそうです。
端末上で動くモデルについては、規模として近いInternVLとかQwen、それとGemmaというものと比較されていた記憶があります。一方でサーバー側の大きめなモデルはLlamaやQwen、あとGPT-4oなんかとも比べられていましたね。Appleの端末用モデルは規模が大きめなInternVLやQwenより有利に見える時もありましたし、Gemmaとは結構拮抗していた場面もちらほら。ただサーバーモデルになるとQwenより処理負荷が半分以下くらいなのに成績では上回ることも。でもLlamaやGPT-4oには少し届かなかった感じでしょうか。
画像応答について人間による評価――これもちょっと興味深い話でして、「どっちの回答が好ましい?」という並列比較だったと思います。図表で割合みたいなものが示されていましたけれど、大雑把に言うとApple側にも支持票がそこそこ入っていた印象です。
汎用的な機能だけじゃなくて、「アダプター」という仕組みによる特定用途向け検証も行われています。たとえばビジュアルインテリジェンスという機能でイベント案内チラシからカレンダー登録を自動生成する、といった流れを想像してください。そのために色んな場所・角度・状況で撮影されたチラシ画像を集めたりして、「日付」「場所」など必要情報をちゃんと取り出せるかどうか確認されていました。
責任あるAI開発――このテーマについてはApple社内でも重視されている雰囲気があります。「ユーザー主導」を意識したツール設計とか、「世界中それぞれ違う利用者像」を反映させる姿勢とか。それだけじゃなく業界水準でも高水準と言われるプライバシー保護策を基盤に据えているようです。このへん、一連のAI機能やその下支えとなるモデル全体にも反映されていて…。まあ細部まで徹底している…と言うより「各段階ごとに原則への配慮」が随所に見受けられる、と言った方が近いかもしれません。
最後になりますが、本当に全体として見ると「ユーザー自身による目標達成をそっと後押しする」方向性だったり、「世界中どこでも違和感なく使えること」を地道に追求している点なんかが特徴と言えそうです。
多言語対応から安全性まで徹底比較した評価結果が明らかに
AIのツールやモデルに関して、ステレオタイプやバイアスをできるだけ持ち込まないようにする取り組みは、なんとなくずっと続いている感じがします。開発の段階でも細かい配慮がされていることが多いようで、たとえば設計からトレーニング、機能追加、それに品質チェックまで、一通り見直しをしている印象です。ただ、それでも完璧とは言いきれないので、ユーザーから寄せられる意見も参考にしながら、徐々に改善していく方針みたいですね。
プライバシー保護にもそれなりに力を入れているようです。端末側で処理を行う仕組みとか、「プライベートクラウドコンピュート」と呼ばれている何か新しいインフラなどが導入されていて、個人情報やユーザーとのやり取りは学習材料として直接使っていないらしい、と聞いたことがあります。
こうした考え方は製品作りの全体にも広がっていて、デザインやポリシー策定だけじゃなく、その後の評価とか対応策なんかにも影響しているのでしょう。アップルがAIについて責任ある姿勢を重視してきた話は有名ですが、その一環として、大げさではない範囲で基盤モデル固有のリスク(幻覚的な出力とかプロンプトインジェクションへの脆弱性など)にも気をつけてきたそうです。「セーフティタクソノミー」という言葉も時折耳にしましたが、この枠組みで内容ごとの慎重な扱い方を決めている雰囲気です。
安全性チェックも二つくらいやり方があります。基盤モデルそのものについては社内外の人手による評価と自動判定、それから他社モデルとも比べたりしています。要約とか質問応答、ブレストっぽい作業など、高リスクと言われる話題についても独自の検証用データセットで確認するという流れですね。一方、それぞれの機能単位ではユーザー視点で困った事態にならないか重点的にテストしたり、特定アプリ向けセンシティブなケースも想定してチェック項目を増やす傾向があります。
ちなみに「Foundation Models Framework」と呼ばれる開発キット? それ自体にも安全対策が組み込まれていて、有害な入力・出力へのガードレール的な仕掛けが用意されています。さらにアプリ設計者・開発者向けには「Generative AI Human Interface Guidelines」なる資料集なども提供中だそうで、自分たち用以外でも安全対策を浸透させたいという狙いでしょうか。
新しくサポートする言語や地域圏が増えるごとに、安全性確保への対応範囲も広げてきた経緯があります。その過程では法律上必要となる規制への適合だけじゃなく、多様な文化背景への配慮も加わってくるようです。一部では外部データソースを活用したり、社内外の法務・語学・文化担当とも協議しつつ、「前例」を参照した判断も採用された模様。
多言語利用時のリスク軽減策としては、大雑把にはまず基盤モデル段階で多言語整合性調整という工程、その後個別機能ごとのアダプター追加――みたいな二段階構成だったと思います。あと、有害プロンプト捕捉目的のガードレール系モデルには各言語専用訓練データも付与されており、多言語型アダプターとうまく併用して運用されていた気配ありです。
文化固有リスクや偏見抑止についてはカスタマイズされたデータセット作成にも着手済み。評価用データセット自体も地域・言語ごと少しずつ拡張されていましたね。その際は機械翻訳や人工生成データもうまく混ぜながら、それぞれ母国語話者による最終調整工程が加わっていた――そんな話でした。
プライバシー保護にもそれなりに力を入れているようです。端末側で処理を行う仕組みとか、「プライベートクラウドコンピュート」と呼ばれている何か新しいインフラなどが導入されていて、個人情報やユーザーとのやり取りは学習材料として直接使っていないらしい、と聞いたことがあります。
こうした考え方は製品作りの全体にも広がっていて、デザインやポリシー策定だけじゃなく、その後の評価とか対応策なんかにも影響しているのでしょう。アップルがAIについて責任ある姿勢を重視してきた話は有名ですが、その一環として、大げさではない範囲で基盤モデル固有のリスク(幻覚的な出力とかプロンプトインジェクションへの脆弱性など)にも気をつけてきたそうです。「セーフティタクソノミー」という言葉も時折耳にしましたが、この枠組みで内容ごとの慎重な扱い方を決めている雰囲気です。
安全性チェックも二つくらいやり方があります。基盤モデルそのものについては社内外の人手による評価と自動判定、それから他社モデルとも比べたりしています。要約とか質問応答、ブレストっぽい作業など、高リスクと言われる話題についても独自の検証用データセットで確認するという流れですね。一方、それぞれの機能単位ではユーザー視点で困った事態にならないか重点的にテストしたり、特定アプリ向けセンシティブなケースも想定してチェック項目を増やす傾向があります。
ちなみに「Foundation Models Framework」と呼ばれる開発キット? それ自体にも安全対策が組み込まれていて、有害な入力・出力へのガードレール的な仕掛けが用意されています。さらにアプリ設計者・開発者向けには「Generative AI Human Interface Guidelines」なる資料集なども提供中だそうで、自分たち用以外でも安全対策を浸透させたいという狙いでしょうか。
新しくサポートする言語や地域圏が増えるごとに、安全性確保への対応範囲も広げてきた経緯があります。その過程では法律上必要となる規制への適合だけじゃなく、多様な文化背景への配慮も加わってくるようです。一部では外部データソースを活用したり、社内外の法務・語学・文化担当とも協議しつつ、「前例」を参照した判断も採用された模様。
多言語利用時のリスク軽減策としては、大雑把にはまず基盤モデル段階で多言語整合性調整という工程、その後個別機能ごとのアダプター追加――みたいな二段階構成だったと思います。あと、有害プロンプト捕捉目的のガードレール系モデルには各言語専用訓練データも付与されており、多言語型アダプターとうまく併用して運用されていた気配ありです。
文化固有リスクや偏見抑止についてはカスタマイズされたデータセット作成にも着手済み。評価用データセット自体も地域・言語ごと少しずつ拡張されていましたね。その際は機械翻訳や人工生成データもうまく混ぜながら、それぞれ母国語話者による最終調整工程が加わっていた――そんな話でした。
責任あるAI開発のためにAppleが守っている4つの原則
いろんな機能ごとに、それぞれの地域独自のリスクを見つけるために、どうやら人によるレッドチーミングみたいなこともしているらしい。ユーザーからのフィードバックも絶えず集めているそうで、例えばImage Playgroundという機能なら、画像生成結果に「いいね」や「よくないね」をタップしたり、気が向けばコメントも添えられる。アプリ開発者だったらFeedback Assistantで意見を送れるんだとか。このあたりのユーザーや開発者から届く声、それと評価データや何かしら他の指標も交えて、Apple Intelligence関連の機能やモデルっていうのは継続的に調整されていくらしい。
……それで結論っぽい話になるけど、Appleが力を入れてる言語基盤モデル、その効率性とか能力をもっと上げていきたいって考えてるみたい。たぶん今後、多様な便利機能がソフトウェア全体へ自然に溶け込んで、日本語含む世界中の多くの言語でも使えるようになってくるだろう、と予想できそう。あと、新しい「Foundation Models Framework」と呼ばれるもののおかげで、開発者もオンデバイス向け言語モデルへ直接アクセスできるようになったみたいなんだよね。AI推論処理も追加コストなしで使わせてもらえるし、ごく簡単なコードだけ書けばテキスト抽出とか要約といったこともアプリ内ですぐ実現できそう。
Apple側ではプライバシー重視とか責任あるAI運用を大事にしているっていう姿勢は変わらないみたい。ただ、この先モデル自体についてさらに細かなアップデート情報なんかは技術レポート形式でまた公開される予定とのこと。
関連情報として…Apple Intelligence向けには、おそらく七十億規模よりちょっと小さいくらい?そんなパラメータ数を持つ基盤モデルが端末上でも動作するよう工夫されている。一方でもっと巨大なサーバー型言語モデルもPrivate Cloud Compute向けに活用されていて、これらはいずれも幅広い作業—まあ文章生成以外にも色々—をそれなり正確かつ効率良くこなせる設計…と言われている。ただ詳細までは全部説明されてなくて、この資料内ではアーキテクチャ概要や訓練データ、その学習工程や何となく具体例っぽい内容まで触れつつ、本当はまだ説明しきれてない部分もちょっと残してある感じ。
2024年初夏ごろだったかな?WWDCイベントでApple Intelligenceが公式発表されたんだけど、この仕組みはiOS18とかiPadOS18、それとmacOS Sequoiaにも深く組み込まれている雰囲気だった。それぞれ日常的な用途に特化した複数タイプの生成系AIが搭載されていて、その時々・その人ごとの行動状況にもある程度合わせて働くらしい(ただどこまで柔軟なのかは実際使ってみないとはっきり分からない)。埋め込み型基盤モデルたちは、「文章を書いたり直したり」「通知整理・要約」「家族友人との会話用イメージ生成」そして「アプリ間操作を少し楽にする」といった領域へ重点的に最適化されてきた経緯がありそう。でも全体像はまだ変化中という印象も残る。